
数据集
Number of Instance: 3060
17 Volunteers × Avg. 5 repetitions × 36 Movements
36 Movements including 20 Falls and 16 Daily Living Activities
25Hz × 6 sensors × 9 axes
特征提取
根据腰部传感器加速度峰值时间点,取左右各2秒的窗口,共25Hz×2s×2+1=101帧,即101×9维数组。而后分别提取max,min,mean,variance,skewness,kurtosis五个值,以及autocorrelation sequence的前11个值,DFT得到5个频率值和5个振幅值。共$(5+11+10)×3×6=1404×1$维向量。
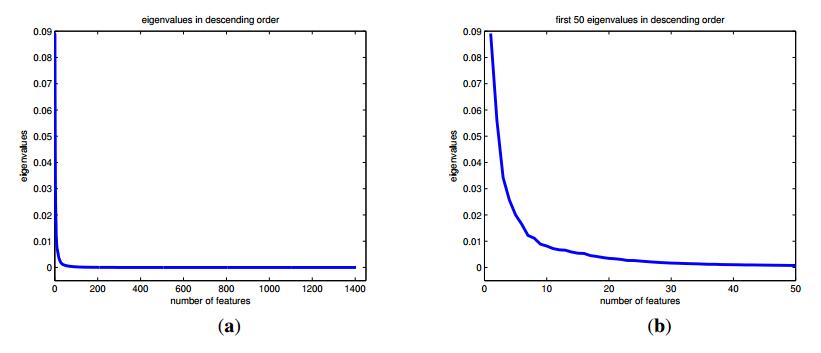
降维
使用PCA(主成分分析)将1404维向量降维至50维。
评估指标
1.正例召回率 $Se=TP/(TP+FN)$
2.反例召回率 $p=TN/(TN+FP)$
3.准确率 $Acc=(TP+TN)/(TP+TN+FP+FN)$
训练集、验证集划分
k-fold交叉验证,k=10
分类算法
1.k近邻算法(k-NN)
2.最小二乘法(LSM)
3.支持向量机(SVM)
4.贝叶斯决策(BDM)
5.动态时间规整(DTW)
6.全连接神经网络(FNN)
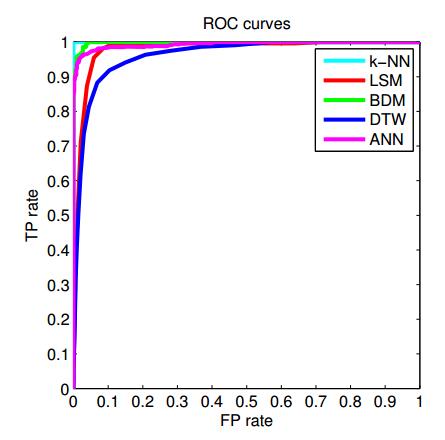
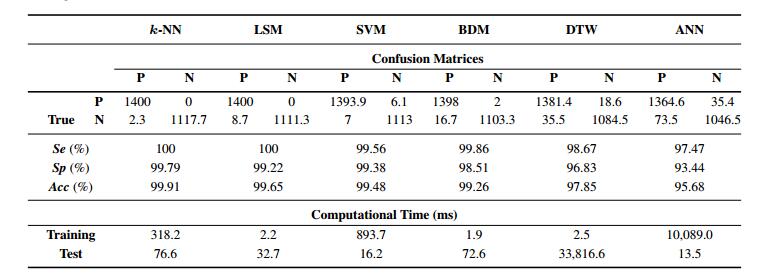
结果
1.准确率 k-NN>LSM>SVM>BDM>DTW>FNN
2.训练时间 FNN>SVM>k-NN>DTW>LSM>BDM
3.测试时间 DTW>k-NN>BDM>LSM>SVM>FNN
4.所有分类器准确率都达到95%以上,其中k-NN,LSM正例召回率达到100%
我认为可改进的地方
1.这篇论文的实验虽然在二分类上取得了十分好的效果,但考虑到数据集采样过于规整,缺少噪音干扰,实际使用时效果可能会变差。所以考虑可以对数据集加入噪声,一方面扩充数据集,另一方面增强模型的泛化能力。
2.如果要进行细粒度分类,由于样本量不足(每个小类的数据仅有几十条)难度可能过大,极易过拟合。使用GAN(生成式对抗网络)生成带有噪音的数据样本可能是一个不错的主意。
3.本实验使用了6组共18个传感器进行数据采集,显然实用性不够高,我们可以考虑mask部分传感器数据进行实验,观察哪一部分的传感器的数据对模型准确率提升最有帮助,从而优化硬件设备需求。