
InnoDB 存储引擎索引概述
InnoDB 存储引擎支持以下几种常见索引:
- B+ 树索引
- 全文索引
- 哈希索引
InnoDB存储引擎支持的哈希索引是自适应的,InnoDB会根据表的使用情况自动生成哈希索引,无法人为干预。B+树索引是目前关系型数据库中查找最为常用和有效的数据库。
B+树索引并不能找到一个给定键值的具体页,而是找到被查找数据行所在的页,然后数据库把页读到内存,再去内存中查找得到要查找的数据。
B+树
B+树的定义
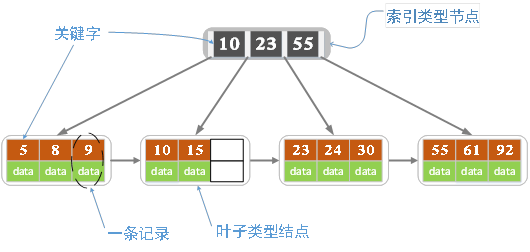
各种资料上 B+ 树的定义各有不同,一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。上图就是一颗阶数为4的 B+ 树。
除此之外 B+ 树还有以下的要求:
B+ 树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
B+ 树与 B 树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
m 阶 B+ 树表示了内部结点最多有 m-1 个关键字(或者说内部结点最多有 m 个子树),阶数 m 同时限制了叶子结点最多存储 m-1 个记录。
内部结点中的 key 都按照从小到大的顺序排列,对于内部结点中的一个 key ,左树中的所有 key 都小于它,右子树中的 key 都大于等于它。叶子结点中的记录也按照 key 的大小排列。
每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
B+ 树的插入操作

若为空树,创建一个叶子结点,然后将记录插入其中,此时这个叶子结点也是根结点,插入操作结束。
针对叶子类型结点:根据 key 值找到叶子结点,向这个叶子结点插入记录。插入后,若当前结点 key 的个数小于等于 m-1 ,则插入结束。否则将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前 m/2 个记录,右结点包含剩下的记录,将第 m/2+1 个记录的key进位到父结点中(父结点一定是索引类型结点),进位到父结点的 key 左孩子指针向左结点,右孩子指针向右结点。将当前结点的指针指向父结点,然后执行第3步。
- 针对索引类型结点:若当前结点key的个数小于等于m-1,则插入结束。否则,将这个索引类型结点分裂成两个索引结点,左索引结点包含前 (m-1) /2个 key ,右结点包含 m-(m-1)/2 个 key ,将第 m/2 个 key 进位到父结点中,进位到父结点的key左孩子指向左结点,进位到父结点的key右孩子指向右结点。将当前结点的指针指向父结点,然后重复第3步。
为减少页的拆分操作,当叶子结点已满,而左右兄弟节点未满时,B+ 树不会着急进行拆分页,而是检查左右兄弟是否没满,如没满则做旋转操作。
B+ 树的删除操作
如果叶子结点中没有相应的key,则删除失败。否则执行下面的步骤:
删除叶子结点中对应的 key。删除后若结点的 key 的个数大于等于Math.ceil(m/2) – 1,删除操作结束,否则执行第2步。
若兄弟结点 key 有富余(大于Math.ceil(m-1)/2 – 1),向兄弟结点借一个记录,同时用借到的 key 替换父结(指当前结点和兄弟结点共同的父结点)点中的key,删除结束。否则执行第3步。
若兄弟结点中没有富余的 key ,则当前结点和兄弟结点合并成一个新的叶子结点,并删除父结点中的 key (父结点中的这个 key 两边的孩子指针就变成了一个指针,正好指向这个新的叶子结点),将当前结点指向父结点(必为索引结点),执行第4步。
若索引结点的 key 的个数大于等于 Math.ceil(m-1)/2 – 1,则删除操作结束,否则执行第5步。
若兄弟结点有富余,父结点key下移,兄弟结点key上移,删除结束。否则执行第6步
6)当前结点和兄弟结点及父结点下移key合并成一个新的结点。将当前结点指向父结点,重复第4步。
注意,通过B+树的删除操作后,索引结点中存在的key,不一定在叶子结点中存在对应的记录。
B+ 树索引
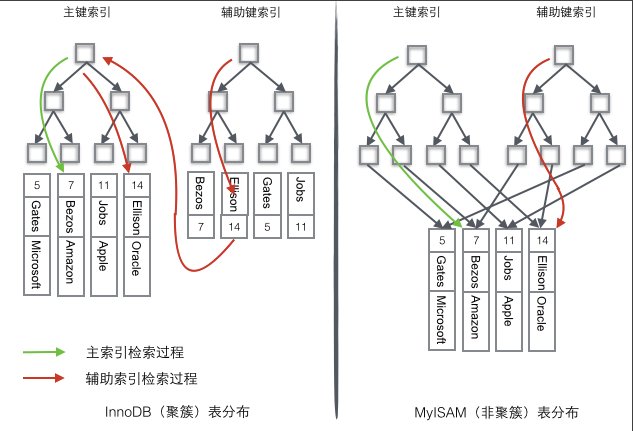
数据库中的 B+ 树索引可以分为 聚集索引( clustered index ) 和 辅助索引( secondary index ),但两者内部都是 B+ 树的,即高度平衡的,区别在于叶子节点是否存放一整行的信息。
聚集索引
InnoDB 存储引擎表是索引组织表,即表中的数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一棵 B+ 树,同时叶子节点存放的即是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。索引组织表中的数据也是索引的一部分。
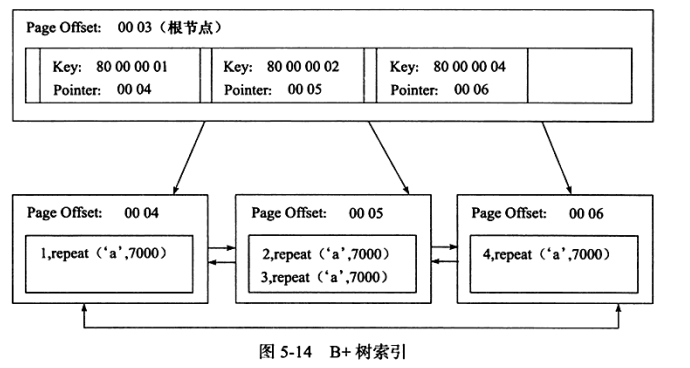
由于实际数据页只能按一棵 B+ 树排序,所以一张表只能拥有一个聚集索引,查询优化器倾向于优先采用聚集索引。因为其能在叶子节点上直接找到数据。此外因为定义了数据的逻辑顺序,聚集索引能够快速访问针对范围值的查询。
聚集索引的存储并不是物理上连续的,而是逻辑上连续的。这其中有两点:一是页通过双向链表链接,页按照主键的顺序排序;二是每个页中的记录也是通过双向链表维护的,所以物理存储上可以不按照主键存储。
聚集索引的另一个好处是:对于主键的排序查找和范围查找很快。
使用命令
explain可以分析数据库对某条语句的查询计划
其中rows为根据所需查找的页数估计的查询行数,并非确切值。
辅助索引
对于辅助索引(也称非聚集索引),叶子节点包含键值和一个书签( bookmark ),书签即相应的行数据的聚集索引键。因此通过辅助索引来寻找数据时,InooDB 存储引擎会遍历两次索引,一次辅助索引和一次主键索引。
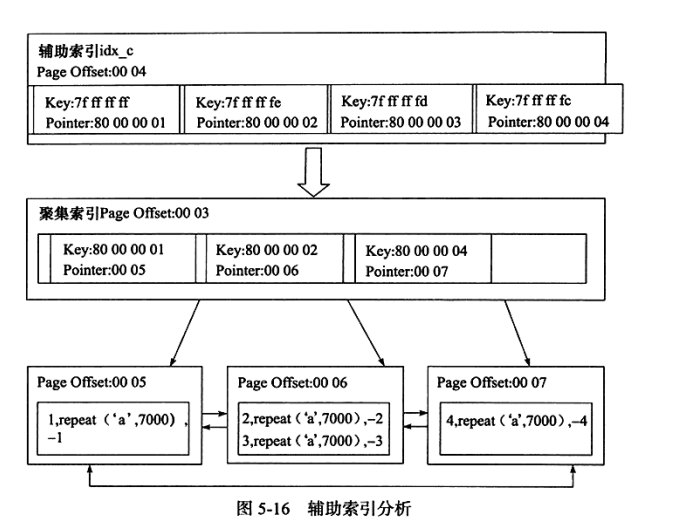
MyISAM 存储引擎使用堆组织表( heap organize table, HOT ),堆表上的索引都是非聚集的,主键与非主键的区别只是是否唯一且非空( NOT NULL )。索引和文件是分开的,随机存储。此时书签只是一个行标识符,使用如“文件号:页号:槽号”的格式来定位实际的行数据。
因此,堆表的书签使得非聚集查找比索引组织表的主键书签方式更快,特别是非聚集索引的离散读取。但一般数据库都可以通过实现预读( read ahead )技术来避免多次的离散读操作。
B+ 树索引的分裂优化
前面介绍 B+ 树插入时的分裂是最简单的情况,与实际数据库中 B+ 树索引的情况略有不同。
传统B+树页面分裂操作分析:
- 50%分裂策略的优势:
分裂之后,两个页面的空间利用率是一样的,如果新的插入是随机在两个页面中挑选进行,那么下一次分裂的操作就会更晚触发; - 50%分裂策略的劣势:
空间利用率不高:按照传统50%的页面分裂策略,索引页面的空间利用率在50%左右;
分裂频率较大:针对如上所示的递增插入(递减插入),每新插入两条记录,就会导致最右的叶页面再次发生分裂;
InnoDB 存储引擎的 Page Header 中以下几个部分用来保存插入的顺序信息:
- PAGE_LAST_INSERT
- PAGE_DIRECTION
- PAGE_N_DIRECTION
通过以上信息, InnoDB 存储引擎可以决定是向左还是向右分裂,同时决定将分裂点记录为哪一个。
- 若插入是随机的,则取页的中间记录作为分裂点的记录,这和之前介绍的相同
- 若往同一方向插入的记录数量为5,并且目前已经定位(cursor)到的记录(待插入记录的前一条记录)之后还有3条记录,则分裂点的记录为定位到的记录后的第三条记录,否则分裂点记录就是待插入的记录。
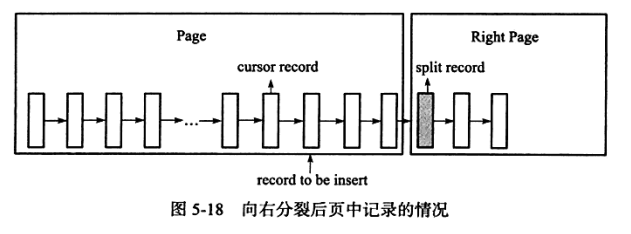
演示1:
- 现在看看一个向右分裂的例子,并且定位到的记录之后还有3条记录,则分裂点记录如下图所示:
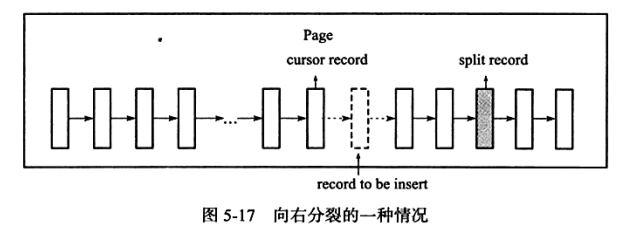
- 上图向右分裂且定位到的记录之后还有3条记录,split record为分裂点记录、最终向右分裂得到下图所示的情况
演示2:
- 在下面演示案例中,分裂点就为插入记录本身,向右分裂后仅插入记录本身,这在自增插入时是普遍存在的一种情况(后面一句没有3条记录了。)
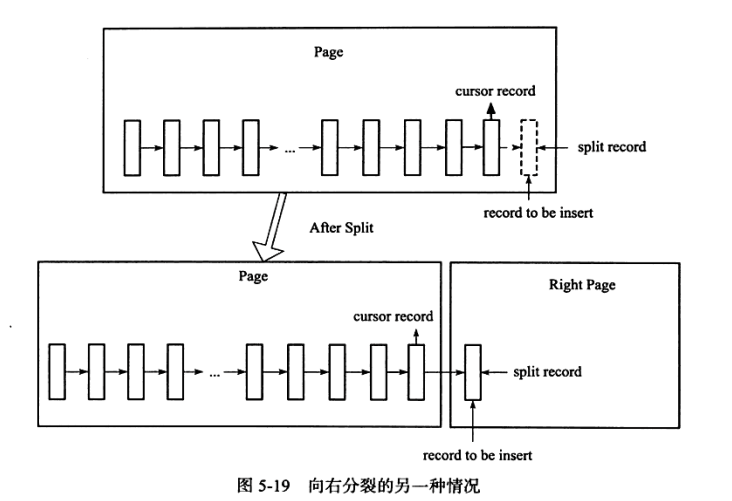
B+树索引的管理
索引管理
索引的创建和删除可以通过两种方法,一种是ALTER TABLE,另一种是CREATE/DROP INDEX。
索引可以索引整个列的数据,也可以只索引一个列的开头部分数据,如前面我们创建的表t,b列为varchar(8000),但是我们可以只索引前100个字段。
Show Index 命令:该命令可以用来查看索引的信息
show index每列的含义如下:
- Table:索引所在的表名
- Non_unique:非唯一的索引,可以看到parimary key是0,因为必须是唯一的
- Key_name:索引的名字,用户可以通过这个名字来执行DROP INDEX
- Seq_in_index:索引中该列的位置,如果看联合索引idx_a_c就比较直观了
- Column_name:索引列的名字
- Collation:列以什么方式存储在索引中。可以是A或NULL。B+树索引总是A,即排序的。如果使用了Heap存储引擎,并且建立了Hash索引,这里就会显示NULL了。因为Hash根据Hash桶存放索引数据,而不是对数据进行索引
- Cardinality:非常关键的值,表示索引中唯一值的数目的估计值。Cardinality/n_rows_in_table 应尽可能接近1,如果非常小,那么用户需要考虑是否可以删除此索引
- Sub_part:是否是列的部分被索引。如果看idx_b这个索引,这里显示100,表示只对b列的前100字符进行索引。如果索引整个列,则该字段为NULL
- Packed:关键字如何被压缩。如果没有被压缩,则为NULL
- Null:是否索引的列含有NULL值。可以看到idx_b这里为yes,因为定义的列允许NULL值
- Index_type:索引的类型。InnoDB存储引擎只支持B+树索引,所以这里显示的都是BTREE
- Comment:注释
SQL语言共分为四大类:数据定义语言DDL,数据操纵语言DML,数据查询语言DQL,数据控制语言DCL。
- 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象:表、视图、索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER
DDL操作是隐性提交的!不能rollback- 数据操纵语言DML
数据操纵语言DML主要有三种形式:
插入:INSERT
更新:UPDATE
删除:DELETE- 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>- 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
GRANT:授权
ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚—-ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL>ROLLBACK
Fast Index Creation技术
待更新
Online Schema Change技术
待更新
Online DDL技术
待更新
参考资料
《MySQL技术内幕 InnoDB存储引擎 第二版》
B树和B+树的插入、删除图文详解
MySQL InnoDB 索引原理
MySQL(InnoDB剖析):25—-B+树索引的管理
从MySQL Bug#67718浅谈B+树索引的分裂优化