
Motivation
当前常用于Fall Detection的数据集大多由志愿者在实验室环境下经由标准化的数据采集流程获取,存在以下几点不足:
- 由于志愿者人数有限,数据集大小一般不足以进行细粒度分类研究,同时易出现过拟合的情况。
- 由于日常生活环境中的运动状况与实验室标准化测试下存在明显的差异,存在大量干扰噪音信息,故基于纯净的实验室采集数据进行训练很难应对复杂的现实生活环境,使得模型泛化能力不足。
综上我们提出使用基于GAN的数据增强技术,一方面增加数据集大小,降低过拟合可能性;另一方面加入可控噪声,提高模型泛化能力,提升其在复杂真实环境中的表现。
Data Augmentation
关于数据增强的介绍参考下文:
Generative Adversarial Network
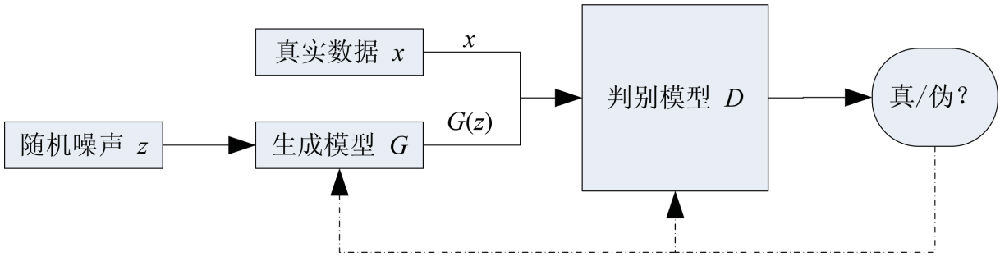
关于GAN的介绍参考下文:
GAN for Data Augmentation
两个主要策略用于检查数据增强效果:
我们可以在“假”数据上训练我们的模型,并检查它在真实样本上的表现。对应的我们在实际数据上训练我们的模型来做一些分类任务,并且检查它对生成的数据的执行情况。如果它在两种情况下都能正常工作,便可以将生成模型中的样本添加到你的实际数据中并再次重新训练,以获得性能上的提升。
GAN Model for Fall Detection Datasets
目前主流的GAN数据增强技术主要用图像数据增强,故模型大多基于卷积神经网络构造而成,对于时序信息处理的GAN相关研究较少。
我们的原始数据为具有时序信息的多维特征向量,而使用不同的数据预处理方式,我们的GAN生成器与判别器的基础模型将有三个选择:
如考虑采取Detecting Falls with Wearable Sensors Using Machine Learning Techniques中的方法,即在特定峰值周围选取窗口,获取局部特征进行处理,则可使用全连接神经网络(FNN)进行构造。
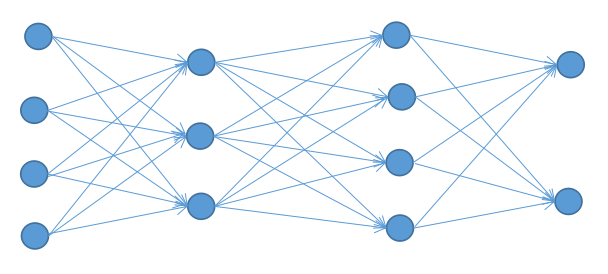
如采取滑动窗口在时间序列上进行切片采样处理,则可使用一维卷积神经网络(1D CNN)进行构造。
如采用基于时间序列的单组特征进行训练,则考虑使用循环神经网络(RNN)进行构造。
Papers
Data Augmentation Generative Adversarial Networks
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
Generative Adversarial Networks Based Data Augmentation For Noise Robust Speech Recognition
BAGAN: Data Augmentation with Balancing GAN
DeLiGAN : Generative Adversarial Networks for Diverse and Limited Data
Conclusion
主要工作:
- 数据集分析,预处理
- 特征工程,特征提取,考虑数据输入方式(决定了基础模型架构选择,特征提取并非必须)
- 模型构造,模型效果评估设计
- 判别器基于原始数据集进行预训练
- GAN对抗训练,获得足够优秀的生成器
- 使用生成器生成大量增强后的数据
- 将生成的数据与原始数据一起用于分类器(与生成器同一模型架构)训练
- 使用现实采集的数据进行模型效果评估(数据采集最好与上述流程同步进行,留给我们的时间不多了)